
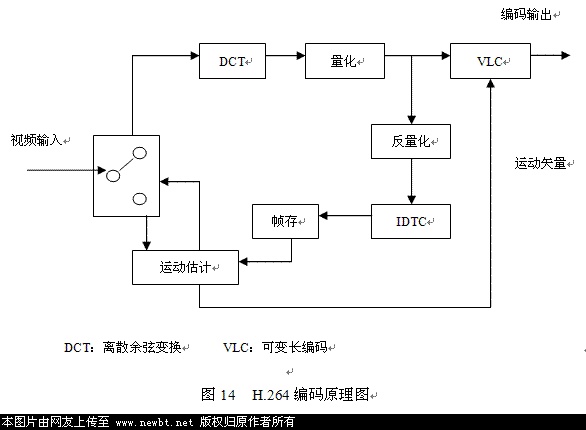
1. H.264����Ľ���
H.264��һ�� ��Ƶ��ѹ��������ȫ����MPEG-4 AVC��������˵�ǡ��ͼ��ר����-4�ĸߵ���Ƶ���롱�����ΪMPEG-4 Part10�������ɹ��ʵ��ű�������ITU-T�涨MPEG�Ĺ��ʱ�����֯ISO/���ʵ繤Э��IEC��ͬ�ƶ���һ�ֻͼ����뷽ʽ�Ĺ��ʱ� ��ʽ������H.264���ƶ�ʱ�ͳ�ֿ����˶�ý��ͨ�Ŷ���Ƶ�����ĸ���Ҫ�������Hϵ�к�MPEGϵ����Ƶ�����о��ɹ�������������Ե����ơ� H.264��Ϊ���µĹ��ʽ��������IP��Ƶ���ϵͳ��������Ҫ�����塣����Ŀǰ��Mpeg4��H.263������Ƚϣ����Ʊ��������¼������棺
1) ѹ���ʺ�ͼ����������
H.264ͨ���Դ�ͳ��֡��Ԥ�⡢֡��Ԥ�⡢�任������ر�����㷨�ĸĽ�����һ����߱���Ч�ʺ�ͼ������������ͬ���ؽ�ͼ�������£�H.264��H.263��Լ50�����ҵ����ʣ���Mpeg4��Լ35�����ҡ�
2) ������Ӧ�Է���
H.264֧�ֲ�ͬ������Դ�µķּ����봫�䣬�Ӷ����ƽ�ȵ�ͼ��������H.264����Ӧ�ڲ�ͬ�����е���Ƶ�� �䣬�������Ժá�H.264�Ļ���ϵͳ����ʹ�ð�Ȩ�����п��ŵ����ʣ��ܺܺõ���ӦIP�����������ʹ�ã����Ŀǰ�������������ý����Ϣ���ƶ����д� �������Ϣ�ȶ�������Ҫ�����塣
3) �������Ϳ����뷽��
H.264���н�ǿ�Ŀ��������ԣ�����Ӧ�����ʸߡ��������ص��ŵ��е���Ƶ���䡣
ʵ��Ӧ���У�ʵʱ�ԺͽϺõ�ͼ���������ϵ͵��������ռ���Լ�������Ӧ�����Ǽ��ϵͳ����Ҫ�������ء�H.264 ��Ƚ���ǰ����Ƶ���������Ҫ������ӿ��Ѻ��Ժߵ�ѹ�����������˺ܴ����ߡ��ۺ����������ڱ�ϵͳ�в���H.264��Ϊ��Ƶ���ݵı��뷽ʽ��
2. H.264�����ʵ��ԭ��

1) ����
H. 264Ϊ��������ʿ��Ƶ�����, ���������ı仯�ķ��ȿ�����12.5 %����, �������Բ���������仯���任ϵ�����ȵĹ�һ�������ڷ����������д����Լ��ټ���ĸ����ԡ�Ϊ��ǿ����ɫ�ı�����,��ɫ��ϵ�������˽�С����������
2) �˶�����
��黮�ַ�ʽ: H. 264 ֧����״���ȵĺ�黮�֣� �仮�ַ�����: 16��16�� 16��8�� 8��16�� 8��8�� 8��4�� 4��8�� 4��4. ���ָ�С�ġ�������״�ĵĺ�黮�֣����к�ͼ����ʵ���˶��������״�� �����˶������ľ��ȣ� ���õ�ʵ���˶����룬 ���ͼ�������ͱ���Ч��. ��������: H. 264 ֧��1/4 ��1/8 ���ȵ��˶������� ʹ��һ��6 ��ͷ�˲����������������ĵ�1/2 ���������� �����Բ�ֵ���1/4 ���������� ��8 ��ͷ�˲���ʵ��1/8 ���ؾ��ȡ� ��ο�֡ģʽ: H. 264 �ڶ������Ե��˶����л�����Ԥ��ʱ�� ��ο�֡�����ṩ���õ�Ԥ��Ч����
3) ֡��Ԥ��
4) �任����
5) �ر���
3 H.264�����㷨��ʵ��
��H.264�������ʵ�ֹ����У�������Ŀǰ������Ӧ����㷺�Ŀ�Դ������X.264��Ϊʵ�ֵĻ�����X.264��JMϵ�б�������T.264��������� ������������ܺͳ�ɫЧ��������X.264û���ṩֱ�ӵĿ���API�������ڱ�ϵͳ�еı��벿�����·�װ��X.264�ı���API����������ϵͳ����ƺ� ʹ�á������DZ�ϵͳ��H.264����ľ���ʵ�ֹ��̣�
1) RGB��YUV��ɫ�ռ��ת��
��ϵͳ��ͨ��Logitech����ͷ��õ���Ƶ����ΪRGB24��ʽ������X.264��������Ϊ����YUV��4��2��0����ͼ���Ӳ�����ʽ����ˣ��ڱ� ��ǰ��Ҫ��RGB��ɫ�ռ�ת��ΪYUV����ɫ�ռ䡣ʵ�ֵĺ���������InitLookupTable�������ڳ�ʼ��ɫ�ʿռ�ת����
RGB2YUV420��int x_dim, int y_dim, unsigned char *bmp, unsigned char *yuv, int flip��������ʵ�ʵ�ת�����������۵��������ԣ�����ͼ���Ӳ�����ʵ�ʵ�ͼ���С�Ѿ���СΪ����ǰ��1.5�������㣬����С��һ�����������
2) ����H.264�������
ʹ��x264_param_default��x264_param_t *param���Ե�ǰ��Ҫ�����ͼ������������á���������֡������param .i_frame_total��������ͼ��ij����Ⱥ߶ȣ�param .i_width��param .i_height������Ƶ���ݱ�����(param .rc.i_bitrate) ����Ƶ����֡�ʣ�param .i_fps_num���Ȳ����������ã�����ɱ���ǰԤ���á�
3) ��ʼ��������
���ϲ��е�������Ϊ��������ʼ���IJ�����x264_t *x264_encoder_open ( x264_param_t *param )�������ʼ��ʧ�ܽ�����NULL����������Ҫ�Ա�������ʼ��������д�����
4) �������ռ�
�����������ʼ���ɹ�������ҪΪ���δ��������ڴ�ռ�
Void x264_picture_alloc��x264_picture_t *pic, int i_csp, int i_width, int i_height����
5) ͼ�����
�����ϲ����ʼ�����������Ϊ�������룬ʹ������ķ������б��룺
int x264_encoder_encode( x264_t *h,x264_nal_t **pp_nal, int *pi_nal,x264_picture_t *pic_in,x264_picture_t *pic_out )��
6) ��Դ����
������ɺ���Ҫ����ϵͳ��Դ�رձ�������ʹ�����º�������ʵ�ֻ��ա�
void x264_picture_clean( x264_picture_t *pic )��
void x264_encoder_close( x264_t *h )��
���ˣ������H.264���룬������������������С�����ǿ��ԶԱ�������������صĽ�һ��������
4 H.264�����㷨������Դ����
�ļ���VideoEncoderX264.h
class CVideoEncoderX264 :
{
public:
CVideoEncoderX264(void);
~CVideoEncoderX264(void);
virtual bool Connect(CVideoEnDecodeNotify* pNotify, const CVideoEnDecodeItem& Item);
virtual void Release(void);
virtual void Encode(BYTE* pInData, int nLen, BYTE* pOutBuf, int& nOutLen, int& nKeyFrame);
private:
x264_picture_t m_Pic;
x264_t *h;
x264_param_t param;
void Flush(void);
};
�ļ���VideoEncoderX264.cpp
bool CVideoEncoderX264::Connect(CVideoEnDecodeNotify* pNotify, const CVideoEnDecodeItem& Item)
{
CBase::Connect(pNotify, Item);
ParseSize(Item.m_stSize);
x264_param_default( ¶m );
param.i_threads = 1;
param.i_frame_total = 0;
param.i_width = m_nWidth;
param.i_height = m_nHeight;
param.i_keyint_min = Item.m_nKeyInterval;
param.i_keyint_max = Item.m_nKeyInterval * 10;
param.i_fps_num = Item.m_nFps;*/
param.i_log_level = X264_LOG_NONE;
if( ( h = x264_encoder_open( ¶m ) ) == NULL )
{
return false;
}
/* Create a new pic */
x264_picture_alloc( &m_Pic, X264_CSP_I420, param.i_width, param.i_height );
return true;
}
void CVideoEncoderX264::Release(void)
{
Flush();
x264_picture_clean( &m_Pic );
x264_encoder_close( h );
CBase::Release();
}
void CVideoEncoderX264::Encode(BYTE* pInData, int nLen, BYTE* pOutBuf, int& nOutLen, int& nKeyFrame)
{
if(nLen != param.i_width * param.i_height * 3)
return;
param.i_frame_total ++;
memcpy(m_Pic.img.plane[0], pInData, param.i_width * param.i_height);
memcpy(m_Pic.img.plane[1], pInData + param.i_width * param.i_height, param.i_width * param.i_height / 4);
memcpy(m_Pic.img.plane[2], pInData + param.i_width * param.i_height * 5 / 4, param.i_width * param.i_height / 4);
m_Pic.i_pts = (int64_t)param.i_frame_total * param.i_fps_den;
static x264_picture_t pic_out;
x264_nal_t *nal = NULL;
int i_nal, i;
if( &m_Pic )
{
m_Pic.i_type = X264_TYPE_AUTO;
m_Pic.i_qpplus1 = 0;
}
//TraceTime("x264_encoder_encode begin");
if( x264_encoder_encode( h, &nal, &i_nal, &m_Pic, &pic_out ) < 0 ) {
return;
}
//TraceTime("x264_encoder_encode end");
int nOutCanUse = nOutLen;
nOutLen = 0;
for( i = 0; i < i_nal; i++ )
{
int i_size = 0;
if( ( i_size = x264_nal_encode( pOutBuf + nOutLen, &nOutCanUse, 1, &nal[i] ) ) > 0 )
{
nOutLen += i_size;
nOutCanUse -= i_size;
}
}
nKeyFrame = pic_out.i_type==X264_TYPE_IDR;// || (pic_out.i_type==X264_TYPE_I && coCfg->x264_max_ref_frames==1);
}
void CVideoEncoderX264::Flush(void)
{
x264_picture_t pic_out;
x264_nal_t *nal;
int i_nal, i;
int i_file = 0;
if( x264_encoder_encode( h, &nal, &i_nal, NULL, &pic_out ) < 0 ){
}
}

�ܳ�һ��ʱ��û��д�����ˣ�ԭ��ܶࡣSVC��ص��о��ʹ����ƽ�����ʱֹͣ�ˣ� ��Ϊ��̫�������ѧϰ�Ϳ�����SVC����Ƶ�����ͺʹ������ص������кܴ�DZ���ģ���������ζ�������ʺ������������繤��Ӧ�á�������š���������Ȳ����ܶ��˶�3D��Ƶ����Ȥ������������������Ƶʱ���������Ĵ���3D��ʼ��Ҳ�������Ĵ�Ļ�ˡ� 
3D��Ƶ�����������˱���뷶�룬����Ҫ�������Ӳ������Ⱦ����Ƶ�ؼ�������ϣ�����е�����ȥ�����������ʱ�������ǿ����֡�
��Ҫ������Щ���ֵĻ��⣬���껹��̤̤ʵʵ��ȥ̽��һЩ����֪ʶ���о������������X264��FFMPEG������ݵ�����̽�֣��������¿�չMVC �ͻ����Ӿ����ѧϰ������ѻ���ͼ�������㷨���¸�ϰ������д��С�Ჩ�͡��ȴ�һ�еĸ�������ȥ����Ƶ�����������ѵ��������Ŀ�꣬ȫϢ��Ƶ������
��һ�ε����½�����X264�Ķ��̹߳��̣�Ҳ����˵�Dz��б�����̡�
1. ���벢�б����x264
��X264�İ��������п��Կ���������--threads����Ե������е��߳��������ǵ������X264���룬��ͼ����ͷ��YUV���б����ʱ�� �������Լ���˫�˼�����ϣ�ֻ�ܷ���50%��Ч�ʣ���ʹʹ��--threads n Ҳ�����£���ʾ����û�д�pthread֧�֡�Pthreads������һ�� C�����������͡������볣�������� pthread.h ͷ�ļ���һ���߳̿�ʵ�֡���1��
����Ͱ�����windows��ʵ��pthread�汾��X264�������д�����£�
2009��3�µ�66�汾
1. ��http://sourceware.org/pthreads-win32/ ����pthread��win32�汾�������е�include��lib���뵽VC++������Ŀ¼��ȥ��
2. ����Ŀ���Եġ�C/C++ -> Ԥ������ ->Ԥ���������м���HAVE_PTHREAD��
3. ��osdep.h�ļ���������#ifdef USE_REAL_PTHREAD����
#pragma comment(lib, "pthreadVC2.lib")
����pthreadVC2.lib�����±��롣
2009��10�µ�77�汾
4. ����Ŀ���Եġ�C/C++ -> Ԥ������ ->Ԥ���������м���SYS_MINGW��
�����汾���Լ����ݿ��ܵı���������Ӧ�䡣������Ŀ������ζ��ͬʱ����libx264��x264���������ԡ�
�������ϵ����������X264�Ϳ�����--threads n //n>=2��ʱ������CPU��DZ���ˡ�
2. X264�ı����������
��1���ӿڱ��
��ǰ����д�����½���X264�ı�̼ܹ����ҷ��������Ľӿڣ����ڽ�һ������x264����ô��YUVͼ����H.264����ġ��ڴ�������У��� ��������ͷ�۵���X264�����洦����ŵĶ��̴߳��������ʿ���������Ĵ��룬���ԣ����ォ�ȼ��̣����Ե���Щ��������롣��Ҫ˵�����ǣ����ķ����� �ǰ汾77��2009��10�µİ汾��
�����API�Ȱ汾66����x264_nal_encode��...�����ú����ǽ����ʷ�װ��NAL�����������ŵ�static int x264_encoder_encapsulate_nals( x264_t *h )�У�������Ϊ����API���֡���x264_encoder_encapsulate_nals(...���ֱ� x264_encoder_headers��...����x264_encoder_frame_end��...�������ã��ֱ����ڷ�װ���� ��sps��pps�����������ݵ�������
��2��main����
�Ӵ����main����������ʼ, ��������ܼ����Ƕ�ȡ������Ȼ����롣���˰汾77�������66�汾���ѣ������˲���--preset�����ڶ���һЩԤ��IJ������������ĸ��汾���� �Ŀ����п�֤���ڵ��Գ����ʱ���Ը�����Ҫѡ��Ԥ�����ֵ���������Ĭ��״̬�������FPS��Ƚ�����
�����ص㿼����뺯��static int Encode( x264_param_t *param, cli_opt_t *opt )�� ��������������ʹ�õ�X264��API���Ӵ����ע��ֱ��װ���������Ͳ������ˡ�

���ȣ�����ͨ��x264_encoder_open( param ) �� x264_picture_alloc( ������ʼ���������ͷ����ڴ湦����YUVͼ��ʹ�á����������Կ���������ע�����Ĵ���飬���ǵĹ�������
/* Encode frames */
while(����ͼ���е���������֡){
��������������
}
/* Flush delayed frames */
������ΪB֡���������������B֡�����У���Ҫ�ο����һ��P֡����ЩB֡����ʱ������֡�Ѿ�������������֡��δ������
Encode�������Ĵ����ǽ��б������رպ��ڴ��������ͳ�Ʊ���֡������FPS�ȡ�
��3��֡���뺯��Encode_frame����
��������������������У����庯����
static int Encode_frame( x264_t *h, hnd_t hout, x264_picture_t *pic )
�������������ÿ֡��YUV���ݣ�Ȼ��������nal�������������ľ��幤������API
int x264_encoder_encode( x264_t *h,x264_nal_t **pp_nal, int *pi_nal,x264_picture_t *pic_in,
x264_picture_t *pic_out )
����ɣ���Ӧ����X264������Ҫ�ĺ����ˡ�
��4������x264_encoder_encode����
���������ο�֡�����������£�
static inline int x264_reference_update( x264_t *h )
������h->frames.reference ������Ҫ�IJο�֡��Ȼ����ݲο�֡���еĴ�С���ƣ��Ƴ���ʹ�õIJο�֡��
Ȼ�����ע�ͰѴ����������·�����
/* ------------------- Setup new frame from picture -------------------- */
/* 1: Copy the picture to a frame and move it to a buffer */
��֡�����YUV���ݴ��� x264_frame_t *fenc�У�Ȼ�����һЩ���ʿ��Ʒ�ʽ�ij�ʼ����
/* 2: Place the frame into the queue for its slice type decision */
��fenc�ŵ�slice���������У�Ҳ�������ʿ��Ƶ�һ����
/* 3: The picture is analyzed in the lookahead */
����slice���ͣ���������;����������ں���void x264_slicetype_decide( x264_t *h )�д�����
���������ʿ��Ʒ�����ʱ����������
/* ------------------- Get frame to be encoded ------------------------- */
/* 4: get picture to encode */
ȥ������֡��������h->fenc�У����������ñ��������
/* ------------------- Setup frame context ----------------------------- */
/* 5: Init data dependent of frame type */
����֡��������i_nal_type��i_nal_ref_idc��h->sh.i_type �������IDR֡�����òο�֡���С�
/* ------------------- Init ----------------------------- */
���ݵ�ǰ֡�����ο�֡���У���ǰ�ο�֡������֡���ͷֱ�д��h->fref0��h->fref1�С������������ǵ�����˳��h->fref0��poc�Ӹߵ��ͣ�h->fref1��֮��
/* ---------------------- Write the bitstream -------------------------- */
дNAL����
/* Write SPS and PPS */
�����
/* ------------------------ Create slice header ----------------------- */
��ʼ��slice header����
/* Write frame */
���slice header��slice data
����������
static int x264_encoder_frame_end( x264_t *h, x264_t *thread_current,x264_nal_t **pp_nal, int *pi_nal, x264_picture_t *pic_out )
����NALװ�����ҵ���������״̬�������֡�����ͳ�����ݡ�
��5��static void *x264_slices_write( x264_t *h )
���������x264_encoder_encode����������Ϊ����slice header��slice data�ı��룬���������Ҫ�Ƿֳ�slice group�е�һ��slice��������slice��������
static int x264_slice_write( x264_t *h )
��������Ĵ���黮�����£�
step1. ��ʼ��NAL,����x264_slice_header_write��������ǰ��IJ����������slice header������
step2. �������CABAC�����ʼ���������ġ�
step3. �����飬��������룺
��������Ҫ������������������
x264_macroblock_analyse( h );
x264_macroblock_encode( h );
��֮ǰ�Ĵ�������������ݵĵ��룬���Ĵ����ǶԱ������ݽ����ر��룬����slicedataЭ��д������������coded_block_pattern���������ʿ���״̬����CABAC���������ݵȡ������������鼶�ˣ��Ϳ�����������ı��뵥λ����ô�������İɡ�
��6��x264_macroblock_analyse( h )
����������Ƿ��������ȷ���������ģʽ����I֡����֡��Ԥ��Ͷ�P/B֡�����˶����ƾͷ����ڴ˺��������Ƚ������ȱ��룬��������ɫ�ȡ�ͬ����һ����������ʵ�֡�
step1.
�������ʿ�������x264_mb_analyse_init���������Ĺ��ܰ�������ʼ�����ʿ��Ƶ�ģ�Ͳ��������ʿ�����Ȼ����Lagrangian��ʧ
���Ż��㷨�����Գ�ʼ��lambdaϵ�������Ѹ��������Cost��ΪCOST_MAX������MV��Χ�����پ���Intra��顣
step2. ����h->sh.i_type�����ͣ�I,P,B�����ֱ������ģʽ����ʧ����ۣ����ۼ���ʹ��SATD��������2��������ؽ��ܡ�ͨ������SATD���Դ��¹��Ʊ�����������Ϊ���ѡ������ݡ�
���ȡh->mb.i_type == I_8x8�������������
if( h->mb.b_lossless )
x264_predict_lossless_8x8( h, p_dst, i, i_mode, edge );
else
h->predict_8x8[i_mode]( p_dst, edge );
x264_mb_encode_i8x8( h, i, i_qp );
step3. ����i_mbrd�IJ�ͬ����һЩ�������㡣
(7)x264_macroblock_encode( h )
��ȷ���˺�����ģʽ���ڱ���������I֡ʣ��ĺ���������Ԥ��ͱ��룬����P/B֡���˶������Ͳв������Ҫ���������
�������̷����������Ѿ�������ˣ��ڴ����У��ᷢ�ֺ���Ԥ��ͱ����ɢ���ڲ�ͬ�ĺ���������ԭ���Ƕ���ʧ���Ż���Ҫ��P/B֡�������ԣ���X264�вο�֡���������ʿ��ƣ�֡��Ԥ��Ͷ��̱߳��붼�DZȽ���Ȥ��̽������
3. ���̴߳������
��1)�ĵ����
������X264�Ļ����ܹ������������̷߳��������ĵط���X264�Դ��Ķ��߳̽����ĵ��DZ�����ıض��ĵ����������X264��DOC�ļ����¡��� �������Ĵ����ǣ���ǰ��X264���߳�ģʽ�Ѿ���������slice�IJ��б��룬ת������֡���ͺ�鼶�IJ��У�ԭ����slice������Ҫ����slice group��������������ཱུ�ͱ���Ч�ʡ�ժ��һ��ԭ�����£�
New threading method: frame-based
application calls x264
x264 runs B-adapt and ratecontrol (serial to the application, but parallel to the other x264 threads)
spawn a thread for this frame
thread runs encode in 1 slice, deblock, hpel filter
meanwhile x264 waits for the oldest thread to finish
return to application, but the rest of the threads continue running in the background
No
additional threads are needed to decode the input, unless
decoding+B-adapt is slower than slice+deblock+hpel, in which case an
additional input thread would allow decoding in parallel to B-adapt.��3��
���ϵ�˵����ζ�ţ�X264����B֡�ڱ���ʱ����Ϊ�ο�֡���������˶�����в��С�
��2������״������
��������x264_pthread_create�����õĵط���ֻ����Щ�ط���ʵʵ���ڵĴ������̡߳�
x264_pthread_create( &h->thread_handle, NULL, (void*)x264_slices_write, h )
x264_pthread_create( &look_h->thread_handle, NULL, (void *)x264_lookahead_thread, look_h )
x264_pthread_create( &h->tid, NULL, (void*)read_frame_thread_int, h->next_args )

����ͼ�����п��Կ������ڿ�����--threads 4��x264_slices_write�������Կ���4���߳�ͬʱ���룬��ͬʱ����һ�����̺߳�һ��x264_lookahead_thread������ �̡�x264_slices_write���������ȼ�Ϊ�ͣ�ԭ���ǵ�����
if( h->param.i_sync_lookahead )
x264_lower_thread_priority( 10 );
���ͱ��̵߳����ȼ���read_frame_thread_int�����Ƕ������ϵ���������Ϣ����ΪI/O���ڴ�IJ�ͬ��������Ӧ�÷ֿ��̴߳�����
��x264_encoder_open�����п����ҵ�һ�´��룬���Կ�������x264_slices_write������x264_lookahead_thread�������б�������ר�е������ı���������һ�߳�ʹ�á�
for( i = 1; i < h->param.i_threads + !!h->param.i_sync_lookahead; i++ )
CHECKED_MALLOC( h->thread[i], sizeof(x264_t) );
��3�����ȷ����ָ���߳����������̱߳��룿
����ӡʵ����Կ���������ʹ��--threads 4�IJ���ѡ������ͬʱ����4��x264_slices_write�����̣߳�Ȼ��ÿ����һ��֡��ǰ���һ���̷߳��غ�һ���µı�����������ʹ�� x264_slices_write�����߳�����������4������һ���̵���ش������£�
int x264_encoder_encode( x264_t *h,x264_nal_t **pp_nal, int *pi_nal,x264_picture_t *pic_in,
x264_picture_t *pic_out )
{
...
if( h->param.i_threads > 1)
{
int i = ++h->i_thread_phase;
int t = h->param.i_threads;
thread_current = h->thread[ i%t ];
thread_prev = h->thread[ (i-1)%t ];
thread_oldest = h->thread[ (i+1)%t ];
x264_thread_sync_context( thread_current, thread_prev );
x264_thread_sync_ratecontrol( thread_current, thread_prev, thread_oldest );
h = thread_current;
}
...
/* Write frame */
if( h->param.i_threads > 1 )
{
printf("x264_pthread_create\n");
if( x264_pthread_create( &h->thread_handle, NULL, (void*)x264_slices_write, h ) )
return -1;
h->b_thread_active = 1;
}
else
if( (intptr_t)x264_slices_write( h ) )
return -1;
return x264_encoder_frame_end( thread_oldest, thread_current, pp_nal, pi_nal, pic_out );
...
}
static int x264_encoder_frame_end( x264_t *h, x264_t *thread_current,x264_nal_t **pp_nal, int *pi_nal, x264_picture_t *pic_out )
{
...
if( h->b_thread_active )
{
void *ret = NULL;
x264_pthread_join( h->thread_handle, &ret );
if( (intptr_t)ret )
return (intptr_t)ret;
h->b_thread_active = 0;
}
...
}
���������������Ĵ���ο��Կ�����h�������б��ֵ��̲߳������4���� x264_pthread_create�����������̵߳ĵ��ã�������x264_slices_write�̣߳�Ȼ��thread_oldest��ָ�������ʿغ����ж����裬��ǰ���߳���������4��ʱ��thread_oldestָ�����̣߳�h->b_thread_activeΪ0�����ܽ���x264_encoder_frame_end(������ش��룬���̼߳���ѭ������x264_slices_write�̣߳����߳�����Ϊ4����ʱthread_oldestָ��4���߳��б��ж���췵�ص��Ǹ�����ʱh->b_thread_active=1������x264_pthread_join(�������������߳̾ͽ�������������״̬��ֱ��thread_oldest��ɣ��������ִ������̣߳��Դ˻��ƣ�����ָ������ı����߳�����
��4��x264_lookahead_thread�����̵߳�����
�ڷ�������߳�֮ǰ��������������Ҫ���߳̿��ƺ�����
//���ѵȴ������������������̡߳����û�еȴ����̣߳���ʲôҲ������
#define x264_pthread_cond_broadcast pthread_cond_broadcast
//�Զ�����������(��ִͬ���� pthread_unlock_mutex)�����ȴ�����������������ʱ�̹߳��𣬲�ռ�� CPU
ʱ�䣬ֱ�������������������ڵ��� pthread_cond_wait ֮ǰ��Ӧ�ó�����������������pthread_cond_wait ��������ǰ���Զ����¶Ի���������(��ִͬ���� pthread_lock_mutex)��
#define x264_pthread_cond_wait pthread_cond_wait
���µĴ�����X264��x264_lookahead_thread���뾭�������ĵط���
**************************�����A********************************************
if( h->lookahead->next.i_size <= h->lookahead->i_slicetype_length )
{
while( !h->lookahead->ifbuf.i_size && !h->lookahead->b_exit_thread )
x264_pthread_cond_wait( &h->lookahead->ifbuf.cv_fill, &h->lookahead->ifbuf.mutex );
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );
}
else
{
x264_pthread_mutex_unlock( &h->lookahead->ifbuf.mutex );
x264_lookahead_slicetype_decide( h );
}
�����ǵȴ�����!h->lookahead->ifbuf.i_size && !h->lookahead->b_exit_thread ����������һ�������������������TRUE����Ϊ�������˳��̡߳���ô����ȴ�����ʵ��ifbuf.i_sizeΪ��0.������ش��룬
����� ifbuf.i_size��������x264_synch_frame_list_push�����õ�����ģ������ڵõ�һ��������±���֡�����źš�
slist->list[ slist->i_size++ ] = frame;
x264_pthread_cond_broadcast( &slist->cv_fill );
�� �����A�У�if( h->lookahead->next.i_size <= h->lookahead->i_slicetype_length )�����У�i_slicetype_length��ʾΪ�˽���slice type���ж϶������֡������ֵ��ȡ����h->frames.i_delay���ɴ���ij�ʼ���趨ֵ������Ĭ��Ϊ40����Ҳ����˵Ԥ��40֡���� ֵ������slice type�����á���ʱ����ϸ����slice type�жϵľ���ʵ�������Ĵ��˼���Ǹ������ʣ�GOP��ʧ��״����Ȩ�⣬������֡����ѡ��������ʵʱͨ�ų��ϣ�������B֡��ʹ�ã�Ҳ������Ԥ����ô��֡�������Ĵ���û�����塣
��ͷ������Ĵ������壬�������̣߳��ȴ�����������֡��Ȼ�����ô���������������slice type��Ϊslice������֡��
��5����鼶��IJ���
�����ݽṹx264_frame_t�У��б���x264_pthread_cond_t cv; �ñ����ֱ�����������������ﱻ��װ�������ͻ��ѣ�
void x264_frame_cond_broadcast( x264_frame_t *frame, int i_lines_completed );
void x264_frame_cond_wait( x264_frame_t *frame, int i_lines_completed );
�������DZ����õĵط���
************����B****************from x264_macroblock_analyse( )->x264_mb_analyse_init����
int thresh = pix_y + h->param.analyse.i_mv_range_thread;
for( i = (h->sh.i_type == SLICE_TYPE_B); i >= 0; i-- )
{
x264_frame_t **fref = i ? h->fref1 : h->fref0;
int i_ref = i ? h->i_ref1 : h->i_ref0;
for( j=0; j<i_ref; j++ )
{
x264_frame_cond_wait( fref[j], thresh );
thread_mvy_range = X264_MIN( thread_mvy_range, fref[j]->i_lines_completed - pix_y );
}
}
**************************����C************************************from x264_fdec_filter_row(��
if( h->param.i_threads > 1 && h->fdec->b_kept_as_ref )
{
x264_frame_cond_broadcast( h->fdec, mb_y*16 + (b_end ? 10000 : -(X264_THREAD_HEIGHT <<h->sh.b_mbaff)) );
}
��
����Ĵ���ο��Կ���û���ͼ��һ�еı��룬���ʹ��mb_y*16
-X264_THREAD_HEIGH��ֵ�����Ի���x264_pthread_cond_wait( &frame->cv,
&frame->mutex )��Ҫ�жϵ�������
mb_y*16 -X264_THREAD_HEIGH < thresh = pix_y + h->param.analyse.i_mv_range_thread;
������Ϊһ���������ֵ������ȷ�������ڱ�֡�ĺ���֡�ڱ���ʱ����֡�Ѿ�����������к�飬�Ժ�������֡�Ļ��������������������������ͼ������X264���Ա���������Ϊ��λ�ġ�

voidRGB2YUV420��int x_dim, int y_dim, unsigned char *bmp, unsigned char *yuv, int flip��
rgb2yuv420 (uint32_t *data_rgb, int width, int height,
uint8_t *data_y, uint8_t *data_u, uint8_t *data_v)
ԭ����������
 �ֺţ��� �� С
�ֺţ��� �� С
����Gem,������������Ƶ���ҵĶ������ˣ�������˼��û����������ԭ��~~
ʱ��ִܲ٣��Ұ���ҵȫ�������ˣ������Ĺ�������ʾ�㿴������ʲô��������ָ����~~
��ϸ�Ĵ���˵�����ѺõĽ���(��MFC��)��������������������Ȥ����ʱ�̹�ע�ҵ�Blog: http://hexun.com/ctfysj
���ǿ�ʼ����C++ �����ҽ������������̣�һ����RGB2YUV,��һ����yuv2rgb�ģ������ȿ���RGB2YUV
���Ҳ���~~~
RGB2YUV420 ��ʾ:
�õ�ͼƬ������ҵ�test.bmp,��test.bmp�ļ���������Ŀ¼�� E:\��վ�ļ���\YUV420��RGB�ת��\homework\RGB2YUV
��ת����YUV420ʱ�洢��test.cif
�������������ļ���~~
���룺 0 error(s), 0 warning(s)
����Ч�������� Ӧ�û��а�~~
�����ٿ� RGB2YUV420 ��ʾ
RGB2YUV420 ��ʾ:
���������ɵ�test.cif�ļ���������Ŀ¼�� E:\��վ�ļ���\YUV420��RGB�ת��\homework\yuv2rgb
��ԭ��test.bmp�ļ�
���룺0 error(s), 0 warning(s)
��ԭ���ɣ�������û�п�������ʲô����~~
�����Ĵ��� : �� RGBYUV420����������.txt ���±�����
Ľ������
������ҳ��http://hexun.com/ctfysj
QQ:308463776
˵��������Ĵ�����C\C++ִ�ж����ԣ���C��ʱ�����#include<iostream> ɾ����
�������ϸ˵����Ƶ�����Ƴ�����ʱ�̹�ע�ҵ�Blog: http://hexun.com/ctfysj
RGB to YUV420 ԭ���룺 RGB2YUV.CPP�ļ�
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include<iostream>
//ת������
#define MY(a,b,c) (( a* 0.2989 + b* 0.5866 + c* 0.1145))
#define MU(a,b,c) (( a*(-0.1688) + b*(-0.3312) + c* 0.5000 + 128))
#define MV(a,b,c) (( a* 0.5000 + b*(-0.4184) + c*(-0.0816) + 128))
//��С�ж�
#define DY(a,b,c) (MY(a,b,c) > 255 ? 255 : (MY(a,b,c) < 0 ? 0 : MY(a,b,c)))
#define DU(a,b,c) (MU(a,b,c) > 255 ? 255 : (MU(a,b,c) < 0 ? 0 : MU(a,b,c)))
#define DV(a,b,c) (MV(a,b,c) > 255 ? 255 : (MV(a,b,c) < 0 ? 0 : MV(a,b,c)))
//ֻ����352*288�ļ�
#define WIDTH 352
#define HEIGHT 288
//��BMP
void ReadBmp(unsigned char *RGB,FILE *fp);
//ת������
void Convert(unsigned char *RGB, unsigned char *YUV);
//���
int main()
{
int i=1;
char file[255];
FILE *fp;
FILE *fp2;
unsigned char *YUV = NULL;
unsigned char *RGB = NULL;
unsigned int imgSize = WIDTH*HEIGHT;
if((fp2 = fopen("test.cif", "wb")) == NULL)//�����ļ���
{
return 0;
}
RGB = (unsigned char*)malloc(imgSize*6);
YUV = (unsigned char*)malloc(imgSize + (imgSize>>1));
for(i=1; i<2; i++)
{
sprintf(file, "test.bmp", i);//��ȡ�ļ�
if((fp = fopen(file, "rb")) == NULL)
continue;
printf("���ļ�%s\n", file);
ReadBmp(RGB, fp);
Convert(RGB, YUV);
fwrite(YUV, 1, imgSize+(imgSize>>1), fp2);//д���ļ�
fclose(fp);
}
fclose(fp2);
if(RGB)
free(RGB);
if(YUV)
free(YUV);
printf("���\n");
system("pause");
return 1;
}
//��BMP
void ReadBmp(unsigned char *RGB,FILE *fp)
{
int i,j;
unsigned char temp;
fseek(fp,54, SEEK_SET);
fread(RGB+WIDTH*HEIGHT*3, 1, WIDTH*HEIGHT*3, fp);//��ȡ
for(i=HEIGHT-1,j=0; i>=0; i--,j++)//����˳��
{
memcpy(RGB+j*WIDTH*3,RGB+WIDTH*HEIGHT*3+i*WIDTH*3,WIDTH*3);
}
//˳�����
for(i=0; (unsigned int)i < WIDTH*HEIGHT*3; i+=3)
{
temp = RGB[i];
RGB[i] = RGB[i+2];
RGB[i+2] = temp;
}
}
void Convert(unsigned char *RGB, unsigned char *YUV)
{
//��������
unsigned int i,x,y,j;
unsigned char *Y = NULL;
unsigned char *U = NULL;
unsigned char *V = NULL;
Y = YUV;
U = YUV + WIDTH*HEIGHT;
V = U + ((WIDTH*HEIGHT)>>2);
for(y=0; y < HEIGHT; y++)
for(x=0; x < WIDTH; x++)
{
j = y*WIDTH + x;
i = j*3;
Y[j] = (unsigned char)(DY(RGB[i], RGB[i+1], RGB[i+2]));
if(x%2 == 1 && y%2 == 1)
{
j = (WIDTH>>1) * (y>>1) + (x>>1);
//����i����Ч
U[j] = (unsigned char)
((DU(RGB[i ], RGB[i+1], RGB[i+2]) +
DU(RGB[i-3], RGB[i-2], RGB[i-1]) +
DU(RGB[i -WIDTH*3], RGB[i+1-WIDTH*3], RGB[i+2-WIDTH*3]) +
DU(RGB[i-3-WIDTH*3], RGB[i-2-WIDTH*3], RGB[i-1-WIDTH*3]))/4);
V[j] = (unsigned char)
((DV(RGB[i ], RGB[i+1], RGB[i+2]) +
DV(RGB[i-3], RGB[i-2], RGB[i-1]) +
DV(RGB[i -WIDTH*3], RGB[i+1-WIDTH*3], RGB[i+2-WIDTH*3]) +
DV(RGB[i-3-WIDTH*3], RGB[i-2-WIDTH*3], RGB[i-1-WIDTH*3]))/4);
}
}
}
YUV420 to RGB ԭ���룺 yuv2rgb.cpp�ļ�
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#define WIDTH 352
#define HEIGHT 288
//ת������
double YuvToRgb[3][3] = {1, 0, 1.4022,
1, -0.3456, -0.7145,
1, 1.771, 0};
//����RGB������дBMP�����ع�ע
int WriteBmp(int width, int height, unsigned char *R,unsigned char *G,unsigned char *B, char *BmpFileName);
//ת������
int Convert(char *file, int width, int height, int n)
{
//��������
int i = 0;
int temp = 0;
int x = 0;
int y = 0;
int fReadSize = 0;
int ImgSize = width*height;
FILE *fp = NULL;
unsigned char* yuv = NULL;
unsigned char* rgb = NULL;
unsigned char* cTemp[6];
char BmpFileName[256];
//����ռ�
int FrameSize = ImgSize + (ImgSize >> 1);
yuv = (unsigned char *)malloc(FrameSize);
rgb = (unsigned char *)malloc(ImgSize*3);
//��ȡָ���ļ��е�ָ��֡
if((fp = fopen(file, "rb")) == NULL)
return 0;
fseek(fp, FrameSize*(n-1), SEEK_CUR);
fReadSize = fread(yuv, 1, FrameSize, fp);
fclose(fp);
if(fReadSize < FrameSize)
return 0;
//ת��ָ��֡ ����㲻�Ǵ����ļ� ��Ҫ������
cTemp[0] = yuv; //y������ַ
cTemp[1] = yuv + ImgSize; //u������ַ
cTemp[2] = cTemp[1] + (ImgSize>>2); //v������ַ
cTemp[3] = rgb; //r������ַ
cTemp[4] = rgb + ImgSize; //g������ַ
cTemp[5] = cTemp[4] + ImgSize; //b������ַ
for(y=0; y < height; y++)
for(x=0; x < width; x++)
{
//r����
temp = cTemp[0][y*width+x] + (cTemp[2][(y/2)*(width/2)+x/2]-128) * YuvToRgb[0][2];
cTemp[3][y*width+x] = temp<0 ? 0 : (temp>255 ? 255 : temp);
//g����
temp = cTemp[0][y*width+x] + (cTemp[1][(y/2)*(width/2)+x/2]-128) * YuvToRgb[1][1]
+ (cTemp[2][(y/2)*(width/2)+x/2]-128) * YuvToRgb[1][2];
cTemp[4][y*width+x] = temp<0 ? 0 : (temp>255 ? 255 : temp);
//b����
temp = cTemp[0][y*width+x] + (cTemp[1][(y/2)*(width/2)+x/2]-128) * YuvToRgb[2][1];
cTemp[5][y*width+x] = temp<0 ? 0 : (temp>255 ? 255 : temp);
}
//д��BMP�ļ���
sprintf(BmpFileName, "test.bmp", file, n);
WriteBmp(width, height, cTemp[3], cTemp[4], cTemp[5], BmpFileName);
free(yuv);
free(rgb);
return n;
}
//��� ûɶ����
void main()
{
int i=1;
// for( i=0; i<260; i++)
Convert("test.cif", WIDTH, HEIGHT, i);//���������Convert,��ȡ�ļ��ĵ�i֡
}
//дBMP ���ع�ע
int WriteBmp(int width, int height, unsigned char *R,unsigned char *G,unsigned char *B, char *BmpFileName)
{
int x=0;
int y=0;
int i=0;
int j=0;
FILE *fp;
unsigned char *WRGB;
unsigned char *WRGB_Start;
int yu = width*3%4;
int BytePerLine = 0;
yu = yu!=0 ? 4-yu : yu;
BytePerLine = width*3+yu;
if((fp = fopen(BmpFileName, "wb")) == NULL)
return 0;
WRGB = (unsigned char*)malloc(BytePerLine*height+54);
memset(WRGB, 0, BytePerLine*height+54);
//BMPͷ
WRGB[0] = 'B';
WRGB[1] = 'M';
*((unsigned int*)(WRGB+2)) = BytePerLine*height+54;
*((unsigned int*)(WRGB+10)) = 54;
*((unsigned int*)(WRGB+14)) = 40;
*((unsigned int*)(WRGB+18)) = width;
*((unsigned int*)(WRGB+22)) = height;
*((unsigned short*)(WRGB+26)) = 1;
*((unsigned short*)(WRGB+28)) = 24;
*((unsigned short*)(WRGB+34)) = BytePerLine*height;
WRGB_Start = WRGB + 54;
for(y=height-1,j=0; y >= 0; y--,j++)
{
for(x=0,i=0; x<width; x++)
{
WRGB_Start[y*BytePerLine+i++] = B[j*width+x];
WRGB_Start[y*BytePerLine+i++] = G[j*width+x];
WRGB_Start[y*BytePerLine+i++] = R[j*width+x];
}
}
fwrite(WRGB, 1, BytePerLine*height+54, fp);
free(WRGB);
fclose(fp);
return 1;
}
��Ƶ�ʹ������ص�ַ��
ftp://ctfysj.kongjian.in:***@ctfysj.kongjian.in/��Ƶ��ѧ�ļ�/homework.rar
***�����룬Ϊ����˽�����ܸ��߱��ˣ�������Ҫ����ظ�����
����:
**** �����ݸ����ظ��ſ���� *****
�ļ���: homework.rar
��������: http://cachefile5.fs2you.com/zh-cn/download/d643ef1aee1a19187dd0850c5259e48d/homework.rar
 : �Ƽ�
: �Ƽ�
/*
* This file is from:
* http://mri.beckman.uiuc.edu/~pan/software.html
*
* It doesn't have any copyright notice that I could find.
* This YUV conversion routine has been modified to read the input
* video from the bottom up, to be compatible with glReadPixels.
*/
#include <stdlib.h>
static int RGB2YUV_YR[256], RGB2YUV_YG[256], RGB2YUV_YB[256];
static int RGB2YUV_UR[256], RGB2YUV_UG[256], RGB2YUV_UBVR[256];
static int RGB2YUV_VG[256], RGB2YUV_VB[256];
void InitLookupTable();
/************************************************************************
*
* int RGB2YUV420 (int x_dim, int y_dim,
* unsigned char *bmp,
* unsigned char *yuv, int flip)
*
* Purpose : It takes a 24-bit RGB bitmap and convert it into
* YUV (4:2:0) format
*
* Input : x_dim the x dimension of the bitmap
* y_dim the y dimension of the bitmap
* bmp pointer to the buffer of the bitmap
* yuv pointer to the YUV structure
*
************************************************************************/
int RGB2YUV420 (int x_dim, int y_dim,
unsigned char *bmp,
unsigned char *yuv,
unsigned char *tmp1, unsigned char *tmp2)
{
int i, j;
unsigned char *r, *g, *b, *rgb_line;
unsigned char *y, *u, *v;
unsigned char *uu, *vv;
unsigned char *pu1, *pu2,*pu3,*pu4;
unsigned char *pv1, *pv2,*pv3,*pv4;
int pitch;
pitch = x_dim * 3;
y=yuv;
uu=tmp1;
vv=tmp2;
u=uu;
v=vv;
rgb_line = bmp + pitch * (y_dim-1);
for (i=0;i<y_dim;i++){
r=rgb_line;
g=rgb_line+1;
b=rgb_line+2;
rgb_line -= pitch;
for (j=0;j<x_dim;j++){
*y++=( RGB2YUV_YR[*r] +RGB2YUV_YG[*g]+RGB2YUV_YB[*b]+1048576)>>16;
*u++=(-RGB2YUV_UR[*r] -RGB2YUV_UG[*g]+RGB2YUV_UBVR[*b]+8388608)>>16;
*v++=( RGB2YUV_UBVR[*r]-RGB2YUV_VG[*g]-RGB2YUV_VB[*b]+8388608)>>16;
r+=3;
g+=3;
b+=3;
}
}
//dimension reduction for U and V components
u=yuv+x_dim*y_dim;
v=u+x_dim*y_dim/4;
pu1=uu;
pu2=pu1+1;
pu3=pu1+x_dim;
pu4=pu3+1;
pv1=vv;
pv2=pv1+1;
pv3=pv1+x_dim;
pv4=pv3+1;
for(i=0;i<y_dim;i+=2){
for(j=0;j<x_dim;j+=2){
*u++=int(*pu1+*pu2+*pu3+*pu4)>>2;
*v++=int(*pv1+*pv2+*pv3+*pv4)>>2;
pu1+=2;
pu2+=2;
pu3+=2;
pu4+=2;
pv1+=2;
pv2+=2;
pv3+=2;
pv4+=2;
}
pu1+=x_dim;
pu2+=x_dim;
pu3+=x_dim;
pu4+=x_dim;
pv1+=x_dim;
pv2+=x_dim;
pv3+=x_dim;
pv4+=x_dim;
}
return 0;
}
void InitLookupTable()
{
int i;
for (i = 0; i < 256; i++) RGB2YUV_YR[i] = (int) ((float)65.481 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_YG[i] = (int) ((float)128.553 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_YB[i] = (int) ((float)24.966 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_UR[i] = (int) ((float)37.797 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_UG[i] = (int) ((float)74.203 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_VG[i] = (int) ((float)93.786 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_VB[i] = (int) ((float)18.214 * (i<<8));
for (i = 0; i < 256; i++) RGB2YUV_UBVR[i] = (int) ((float)112 * (i<<8));
}
![]() Parent Directory
|
Parent Directory
| ![]() Revision Log
Revision Log
fixed handling of odd-shaped windows (non-4bit-aligned ones). since teaching the rgb2yuv conversion about these seems to be non-trivial, just use a properly sized imlib image.
/*
* Copyright (c) 2005 Vincent Torri (vtorri at univ-evry fr)
*
* Permission is hereby granted, free of charge, to any person obtaining
* a copy of this software and associated documentation files (the
* "Software"), to deal in the Software without restriction, including
* without limitation the rights to use, copy, modify, merge, publish,
* distribute, sublicense, and/or sell copies of the Software, and to
* permit persons to whom the Software is furnished to do so, subject to
* the following conditions:
*
* The above copyright notice and this permission notice shall be
* included in all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
* EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
* MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
* NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
* LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
* OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
* WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
#include <stdint.h>
/*
* Colour conversion from
* http://www.poynton.com/notes/colour_and_gamma/ColorFAQ.html#RTFToC30
*
* YCbCr in Rec. 601 format
* RGB values are in the range [0..255]
*
* [ Y ] [ 16 ] 1 [ 65.738 129.057 25.064 ] [ R ]
* [ Cb ] = [ 128 ] + --- * [ -37.945 -74.494 112.439 ] * [ G ]
* [ Cr ] [ 128 ] 256 [ 112.439 -94.154 -18.285 ] [ B ]
*/
void
rgb2yuv420 (uint32_t *data_rgb, int width, int height,
uint8_t *data_y, uint8_t *data_u, uint8_t *data_v)
{
int x, y, row_stride = width * 4;
uint8_t *rgb, *Y = data_y, *U = data_u, *V = data_v;
uint8_t u00, u01, u10, u11;
uint8_t v00, v01, v10, v11;
int32_t RtoYCoeff = (int32_t) (65.738 * 256 + 0.5);
int32_t GtoYCoeff = (int32_t) (129.057 * 256 + 0.5);
int32_t BtoYCoeff = (int32_t) (25.064 * 256 + 0.5);
int32_t RtoUCoeff = (int32_t) (-37.945 * 256 + 0.5);
int32_t GtoUCoeff = (int32_t) (-74.494 * 256 + 0.5);
int32_t BtoUCoeff = (int32_t) (112.439 * 256 + 0.5);
int32_t RtoVCoeff = (int32_t) (112.439 * 256 + 0.5);
int32_t GtoVCoeff = (int32_t) (-94.154 * 256 + 0.5);
int32_t BtoVCoeff = (int32_t) (-18.285 * 256 + 0.5);
/* Y plane */
rgb = (uint8_t *) data_rgb;
for (y = height; y-- > 0; ) {
for (x = width; x-- > 0; ) {
/* No need to saturate between 16 and 235 */
*Y = 16 + ((32768 +
BtoYCoeff * *(rgb) +
GtoYCoeff * *(rgb + 1) +
RtoYCoeff * *(rgb + 2)) >> 16);
Y++;
rgb += 4;
}
}
/* U and V planes */
rgb = (uint8_t *) data_rgb;
for (y = height / 2; y-- > 0; ) {
for (x = width / 2; x-- > 0; ) {
/* No need to saturate between 16 and 240 */
u00 = 128 + ((32768 +
BtoUCoeff * *(rgb) +
GtoUCoeff * *(rgb + 1) +
RtoUCoeff * *(rgb + 2)) >> 16);
u01 = 128 + ((32768 +
BtoUCoeff * *(rgb + 4) +
GtoUCoeff * *(rgb + 5) +
RtoUCoeff * *(rgb + 6)) >> 16);
u10 = 128 + ((32768 +
BtoUCoeff * *(rgb + row_stride) +
GtoUCoeff * *(rgb + row_stride + 1) +
RtoUCoeff * *(rgb + row_stride + 2)) >> 16);
u11 = 128 + ((32768 +
BtoUCoeff * *(rgb + row_stride + 4) +
GtoUCoeff * *(rgb + row_stride + 5) +
RtoUCoeff * *(rgb + row_stride + 6)) >> 16);
*U++ = (2 + u00 + u01 + u10 + u11) >> 2;
v00 = 128 + ((32768 +
BtoVCoeff * *(rgb) +
GtoVCoeff * *(rgb + 1) +
RtoVCoeff * *(rgb + 2)) >> 16);
v01 = 128 + ((32768 +
BtoVCoeff * *(rgb + 4) +
GtoVCoeff * *(rgb + 5) +
RtoVCoeff * *(rgb + 6)) >> 16);
v10 = 128 + ((32768 +
BtoVCoeff * *(rgb + row_stride) +
GtoVCoeff * *(rgb + row_stride + 1) +
RtoVCoeff * *(rgb + row_stride + 2)) >> 16);
v11 = 128 + ((32768 +
BtoVCoeff * *(rgb + row_stride + 4) +
GtoVCoeff * *(rgb + row_stride + 5) +
RtoVCoeff * *(rgb + row_stride + 6)) >> 16);
*V++ = (2 + v00 + v01 + v10 + v11) >> 2;
rgb += 8;
}
rgb += row_stride;
}
}
| admin | ViewVC Help |
| Powered by ViewVC 1.0.0 |
|
|

