clq
浏览(120) +
2007-09-10 14:49:58 发表
编辑
关键字:
转自:http://blog.programfan.com/article.asp?id=9737
clq
clq
clq
clq
clq
[图片]
clq
clq
clq
clq
clq
NEWBT官方QQ群1: 276678893

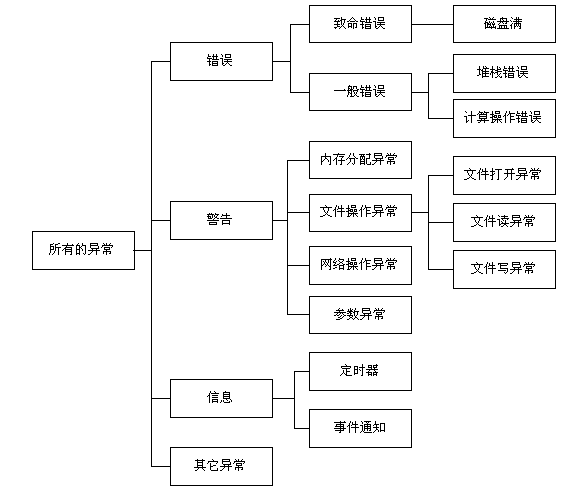 从上面的异常分类来看,它有明显的层次性和继承性,这恰恰和面向对象的继承思想如出一辙,因此用对象来描述程序中出现的异常是再恰当不过的了。而且可以利用面向对象的特性很好的对异常进行分类处理,例如有这样一个例子:
从上面的异常分类来看,它有明显的层次性和继承性,这恰恰和面向对象的继承思想如出一辙,因此用对象来描述程序中出现的异常是再恰当不过的了。而且可以利用面向对象的特性很好的对异常进行分类处理,例如有这样一个例子: